As we all use git every day in our projects and it has made our lives easier by allowing us to collaborate with others more efficiently.Thus it helped us to produce great software that is impacting our lives every day.
What is Git?
In simplest terms Git is distributed version control system that allows us to keep track of our files and helps us collaborate with each other more efficiently while working on a software project. Git was created by Linus Torvalds in 2005 for development of the Linux kernel. It is primarily written in C and other languages such as python,shell, Perl and Tcl`.
Lets Begin Exploring Git
In order to begin I will start by creating a git repo named test/
git init testcommand creates a local repo namedteston our machine that contains.git/folder which contains all the metadata.
drwxr-xr-x 3 hackerman hackerman 4096 May 31 17:48 .
drwx--x--x 71 hackerman hackerman 4096 May 31 17:49 ..
drwxr-xr-x 7 hackerman hackerman 4096 May 31 17:49 .git
In this blog, I will be focusing on objects and ref since they are the most important parts of .git/ directory.
.git
├── branches
├── config
├── description
├── HEAD
├── hooks
│ ├── applypatch-msg.sample
│ ├── commit-msg.sample
│ ├── fsmonitor-watchman.sample
│ ├── post-update.sample
│ ├── pre-applypatch.sample
│ ├── pre-commit.sample
│ ├── pre-merge-commit.sample
│ ├── prepare-commit-msg.sample
│ ├── pre-push.sample
│ ├── pre-rebase.sample
│ ├── pre-receive.sample
│ └── update.sample
├── info
│ └── exclude
├── objects
│ ├── info
│ └── pack
└── refs
├── heads
└── tags
9 directories, 16 files
How Git Actually works
So I will be explaining how everything works under the hood using this simple diagram. As you can see we have three things working directory, staging area and local repo.
When we run git add it creates a snapshot of our file that we are working on and put that file in the staging area and then we run git commit command which saves that snapshot of our file permanently in our local repo.
What happens when we run git add <filename>
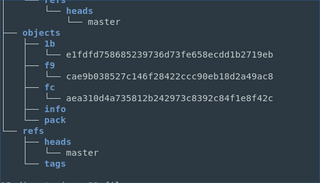
When we run git add command it takes the files from the staging area and saves the file as a copy under objects directory. The file is represented as a blob (Binary Large Object) and that name of the file is generated using SHA-1 hashing algorithm as it was calculated using the contents of the file.
In this case it is represented by f9cae9b and the object can be seen by using the following command git show --pretty=raw f9cae9b.
What happens when we run git commit <filename>
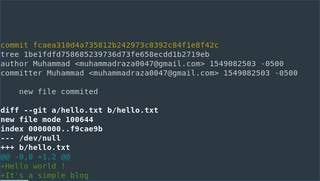
When we run git commit it takes our file from staging and saves as a permanent snapshot in our local repo. When we run git commit command two more objects are created. A tree & A commit
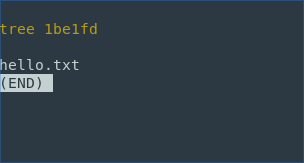
As you can tree is represented by 1be1fd
and commit is represented fcae310. furthermore, if you notice it also has a tree and it represents our directory structure.
If we run git ls-tree <tree> it prompts more us information about our tree and what type of files it contains.

So we have a file named hello.txt in our tree which is represented as a blob object which it refers to f9cae9b. moreover, file permissions are also tracked by git which is represented as 100644 in this case. Git is so intelligent that when we change our file name our raw data isn’t deleted but a new tree is created in our object, therefore, it allows us to change file names easily without losing raw data.
Besides, objects/ directory we also have refs/ and this contains our branches. Branch name acts a reference to the commit. It contains a SHA that is pointing to our commit and it is automatically updated whenever we make a change and commit our file to the repo.
So this is how Git works under the hood. Furthermore, Git uses a data structure called Directed Acyclic Graph and it’s really interesting to see how git works and how it has made collaboration easier for developers.
I hope you enjoyed this post if you think i missed any thing feel free to dm me on twitter Feel to share it among your friends and colleagues.